Chapter 18 e-statの利用方法
18.2 e-statの使い方
- e-statの使い方は2種類ある。
- CSVやエクセルをダウンロードする。
- e-stat APIからデータを直接Rにダウンロードする(推奨)
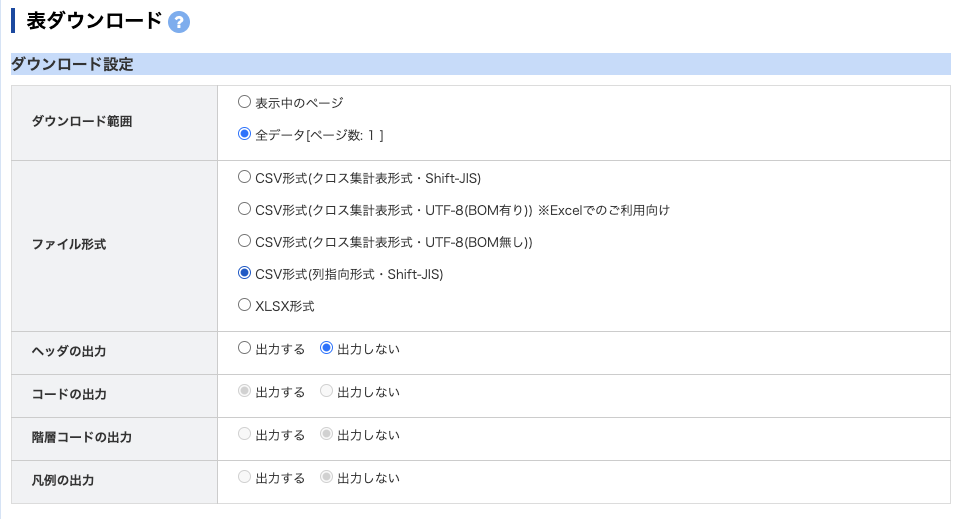
1の方法では、ダウンロードしたいページ(例えばこれ)で、右上の「ダウンロード」ボタンを押すと以下のようなページが現れる。データとして分析するためのファイルを読み込む場合は、「CSV形式(列指向形式・Shift-JIS)」を選択し、ヘッダの出力を「出力しない」にしてダウンロードする。
ダウンロードされたファイルを、自分の作業フォルダなど適切な場所に移して、read_csvなどで読み込ませれば使用することができる。 このファイルはエンコーディングがShift-JISになっているため、そのまま読み込むと文字化けするかエラーが出る。 この問題については、日本語のデータを読み込む際の注意点(#datajpn)を参照してほしい。
18.3 e-stat APIの使い方
一つ一つのファイルをダウンロードするより楽でスムーズな方法がAPIを使う方法だ。
APIとは「アプリケーション・プログラミング・インターフェース(Application Programming Interface)」の略称で、ソフトウェアやプログラム、ウェブサービスの間をつなぐ仕組みのことを指す。
ここでは、e-statという統計情報サービスと、R/R Studioというプログラムの間をつなぐというイメージに当たる。
18.3.1 APIの準備
まず、e-StatのAPI機能のページに行って、ユーザー登録を行う。 メールアドレスを仮登録したら、メールに来たURLから本登録を行う。
本登録を行う際は、大学のGoogleアカウントを使うと、パスワードの入力などが省略できる。
登録を終えて、ログインしたら、「マイページ」の上部メニューから「API機能(アプリケーションID発行)」を選ぶ。
ここで、名称やURLを求められるが、適当で良い。URLに武蔵大学や阿部ゼミのURLでも入れておけばよい。 必要な情報を入力したら「発行」を押すと、appIdというところにアプリケーションIDが発行される。
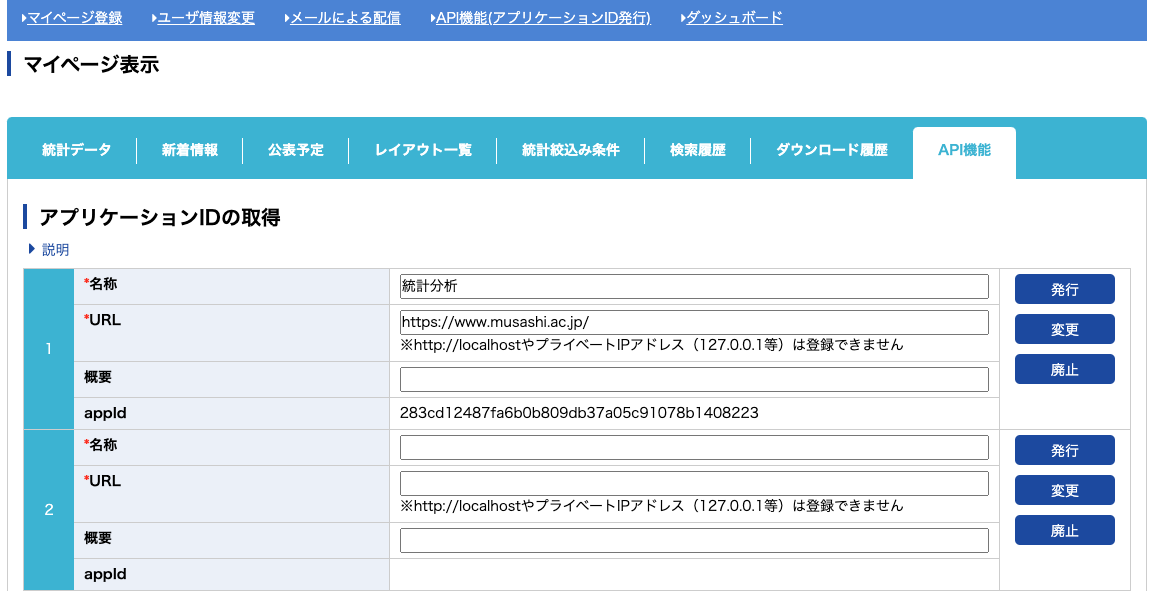
これでAPIを利用する準備は完了である。
18.3.2 estatapiパッケージでデータを利用する
まず、新しいスクリプトを用意しよう。
estatapiというパッケージをインストールする。
そして、いつも通りtidyverseとestatapiパッケージをロードする。
次に、appIDというオブジェクトを作り、ここに自分のアプリケーションIDを読み込ませる。
上のIDは適当なので、自分のIDに置き換えて使う。
例えば、ここでは2018年漁業センサスの第2巻 海面漁業に関する統計(都道府県編)の漁業経営体数・漁船というデータを読み込むとしよう。 e-Statのウェブサイト上で、漁業センサスを検索し、「データベース」を選ぶとこのようなページに飛ぶ。そこから、2018年漁業センサス第2巻を選び、漁業経営体数・漁船を選ぶと、以下のような表が表示される。

その中で、「統計表表示ID」というものをコピーする。

Rに戻って、まずは統計のメタデータ(どのような変数が入っているかなど大まかな情報)をダウンロードする。
これにはestat_getMetaInfoという関数を用いて、appIdという引数には自分のIDがはいったappIDオブジェクトを指定し、statsDataIdには今コピーした統計表表示IDを""で囲んで指定する。
メタ情報の中身を見てみる。
## [1] "cat01" "cat02" ".names"cat01やcat02はデータに含まれる属性が示されている。このデータにはないが、timeというメタデータがあれば、それは時間軸が示されている。
## # A tibble: 5 × 4
## `@code` `@name` `@level` `@unit`
## <chr> <chr> <chr> <chr>
## 1 001 漁業経営体数 1 経営体
## 2 002 漁船_無動力漁船隻数 1 隻
## 3 003 漁船_船外機付漁船隻数 1 隻
## 4 004 漁船_動力漁船_隻数 1 隻
## 5 005 漁船_動力漁船_トン数 1 T実際のデータを取得する。
データの取得にはestat_getStatsDataという関数を用いる。
引数は上と同様に、自分のアプリケーションIDと統計表表示IDをそれぞれ指定する。
これで、datオブジェクトに2018年の漁業センサスから、都道府県別の漁業経営体数や漁船数のデータがダウンロードされた。
データを見てみる。
## # A tibble: 10 × 7
## cat01_code (J118-30-2-001)全国・都道…… cat02_code (J118-30-1-064)基本的項目……
## <chr> <chr> <chr> <chr>
## 1 001 全国 001 漁業経営体数
## 2 001 全国 002 漁船_無動力漁船隻数
## 3 001 全国 003 漁船_船外機付漁船隻数
## 4 001 全国 004 漁船_動力漁船_隻数
## 5 001 全国 005 漁船_動力漁船_トン数
## 6 002 北海道 001 漁業経営体数
## 7 002 北海道 002 漁船_無動力漁船隻数
## 8 002 北海道 003 漁船_船外機付漁船隻数
## 9 002 北海道 004 漁船_動力漁船_隻数
## 10 002 北海道 005 漁船_動力漁船_トン数
## # ℹ abbreviated names: ¹`(J118-30-2-001)全国・都道府県・大海区`,
## # ²`(J118-30-1-064)基本的項目`
## # ℹ 3 more variables: unit <chr>, value <dbl>, annotation <chr>valueという列には異なる変数(経営体数や漁船数)が一気に入ってしまっているので、整然データにはなっていない。
18.3.3 データ加工の例
ここからはデータのハンドリングの復習なので、細かい関数の挙動は該当チャプターで復習してほしい。
dat2 <- dat |>
# 列名を簡単なものに変える
rename("pref" = 2, "item" = 4) |> # 2列目をprefに、4列目をitemに変更
# itemに基づいて、複数の列に分ける
pivot_wider(id_cols = c(cat01_code,pref), # 都道府県(それ以外の項目も含まれているが)ごとに
names_from = "item", # 各列にitemという名前をつけて
values_from = "value") |> # valueという列に入っている値を振り直す
# 不要な行を削除(=必要な行だけ取り出し)
slice(2:40) |> # 1行目は全国、41行目からは海区別のデータが入ってしまっている。都道府県だけほしいので、そこだけ取り出す。
mutate(pref = fct_reorder(pref,cat01_code)) # 都道府県のデータをcat01_codeの番号順の要素データとして定義し直す18.3.4 データ描画の例
詳細については描画についてのチャプターを参照してください。
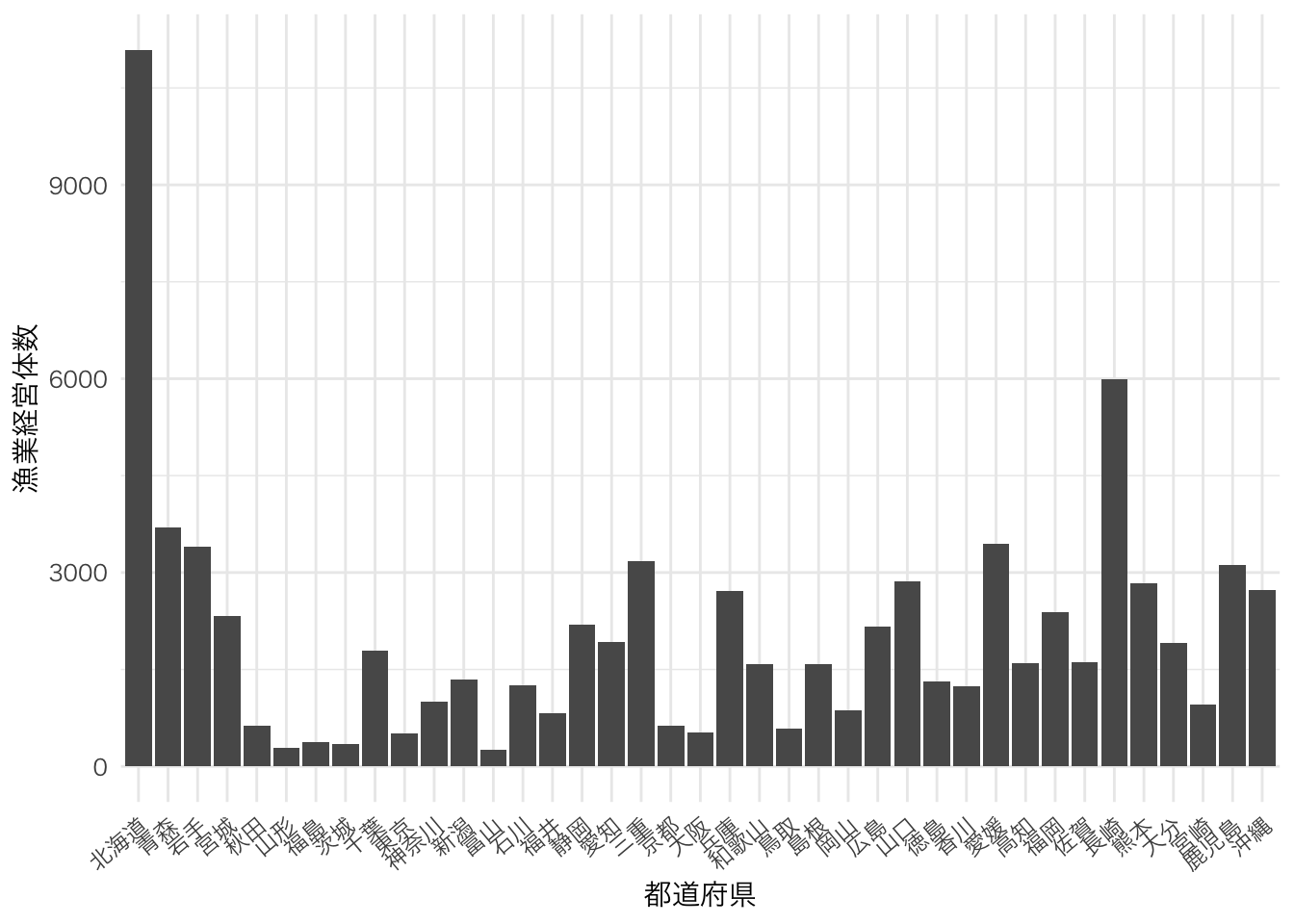
ggplot(data=dat2, aes(x=pref, y=`漁業経営体数`)) +
geom_bar(stat="identity") +
theme_minimal(base_family = "HiraKakuPro-W3") +
labs(x="都道府県",y="漁業経営体数") +
theme(axis.text.x = element_text(angle=40, hjust=1))