Chapter 19 回帰分析結果のレポーティング
19.1 回帰分析結果の報告
回帰分析を行ったら、その結果を報告する。報告の際には、結果を表にして報告するのがスタンダードである。これは、プレゼンテーションやレポート・論文でも同じである。
複数のモデルを比較しやすいようにして表にして見せるのがよい。この見せ方は、結果をきちんと伝える上で大変重要である。この章では、回帰分析の表のアウトプットについて解説する。
19.2 回帰分析の結果の報告
引き続き重回帰分析の章の例を使ってみよう。
「# シミュレーションデータの作成」部分を実行してdat_simというデータを作成しよう。
そのデータを使って、以下のような2つのモデルを推定する。ここではfixestパッケージのfeols()関数を使っている。
model1 <- feols(sales ~ ads + age, data = dat_sim)
model2 <- feols(sales ~ ads + age + income, data = dat_sim)
etable(model1,model2)## model1 model2
## Dependent Var.: 支店の売上 支店の売上
##
## Constant 549.7*** (6.372) 499.6*** (6.860)
## 広告ダミー 86.26*** (2.973) 49.66*** (4.028)
## 店長の年齢(歳) 4.625*** (0.1515) 4.985*** (0.1299)
## 地域の平均所得(万円) 0.0899*** (0.0078)
## _______________ _________________ __________________
## S.E. type IID IID
## Observations 300 300
## R2 0.88607 0.92132
## Adj. R2 0.88530 0.92052
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1fixestパッケージを使っている場合は、etable()関数で回帰分析表をコンソールに表示できることはすでに解説した。

このような結果が出る。
もしくは、etable()を使わなかったり、lm()やlm_robust()などを使ってsummary()関数で結果を表示していると、このような結果がコンソールに出るだろう。
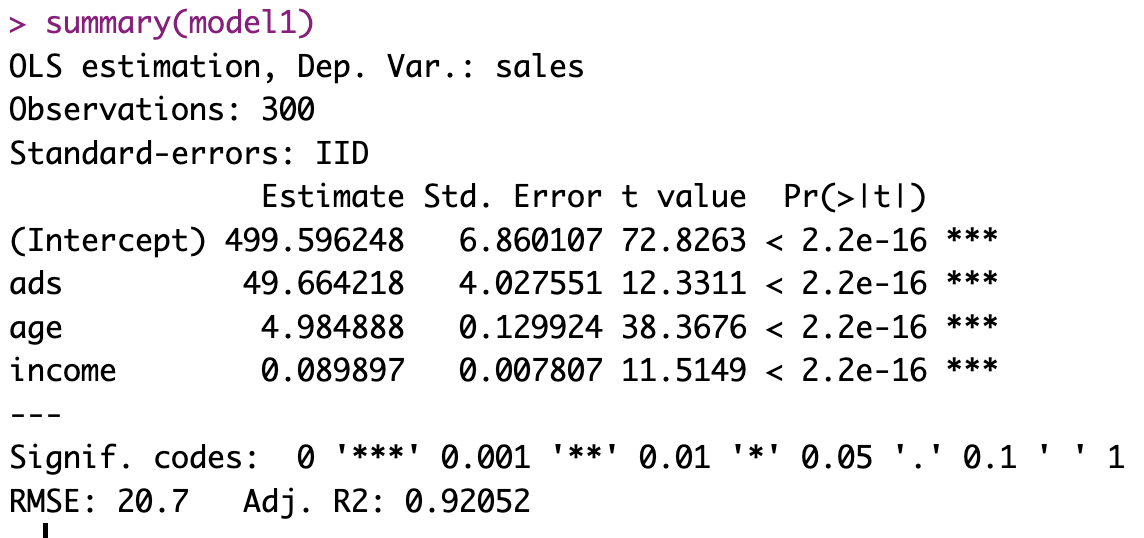
この結果を、テキストとしてコピペしてワードに貼り付けたり、スクリーンショットを撮って図として貼り付けたりするケースが見られるが、そのまま見せるのは良くない。なぜなら、ひとことでいうと美しくないからである。
美しさはバカにはできない。美しくない図表は読者の見る気、理解しようとする気を失わせる。きちんと理解してもらうためには、最低限の「身だしなみ」を整える必要がある。
身だしなみを整える方法として、2つのステップがある。1つは、表としての体裁を整えること。これで8割は決まる。必要な情報を提供することが大事であり、例えば最低限の比較として、summary()を使った結果を並べるよりetable()で比較しやすく見せるのは最初に一歩である。しかし、それだけではだめで、さらに見やすく整える必要がある。
もう一つは、Wordなどの形式にきちんと出力することである。スクリーンショットというアドホックな手法ではなく、きちんとファイル名を指定してファイルを書き出すことで、再現性を高めることができるし、どのファイルがどのようにして生成されたかをコードに残すことができる。さらに、画像ファイルの他にWordやHTML, 上級者向けにはTexなどにも出力することが可能だ。
ここでは、lm()などにも対応した表作成パッケージのmodelsummaryの使い方を解説し、その後etable()を使った表作成も解説する。
19.3 modelsummary()による表作成
まず、modelsummaryというパッケージをインストールする。
例によって、RStudioの右下ペーンのPackagesタブからInstallを押してインストールするか、install.packages("modelsummary")を実行してインストールする。
インストールしたら、コード上部にlibrary(modelsummary)と追加して読み込むのを忘れずに。
19.3.1 表の出力
まず、modelsummary()では、出力したい回帰分析オブジェクトをlist()でまとめる必要がある。
例えば、model1とmodel2を表示したい場合は、list(model1,model2)という形でまとめる。
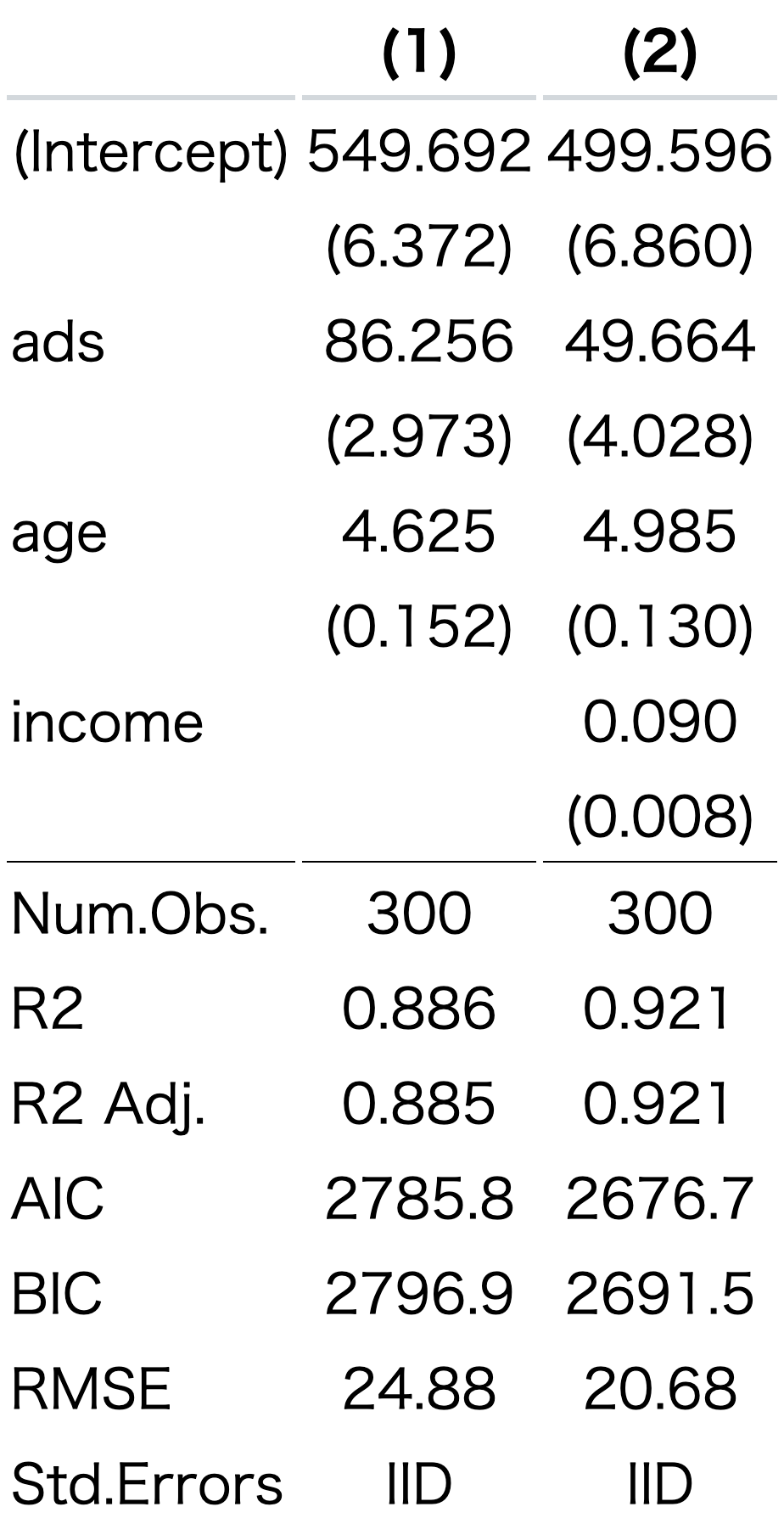
これを実行すると、右下ペーンのViewerに回帰分析表が表示される。
これから、この表を見やすく整えていく。
19.3.2 変数名の設定
19.3.2.1 変数名の変換
モデル推定に直接使用した説明変数の変数名は、読者にとってはわかりにくい。 もっとわかりやすい名前に変えて表に示すほうが親切である。
そのためには、変数名と変換したい名前の「辞書」を作成する。
具体的には、以下のように変数名と変換したい名前を=つなぎ、c()でまとめ、オブジェクトに保存する。
varname_dict <- c(sales = "支店の売上",
`(Intercept)` = "切片",
ads = "広告ダミー",
age = "店長の年齢(歳)",
income = "地域の平均所得(万円)")そして、coef_renameという引数にこの辞書を指定する。
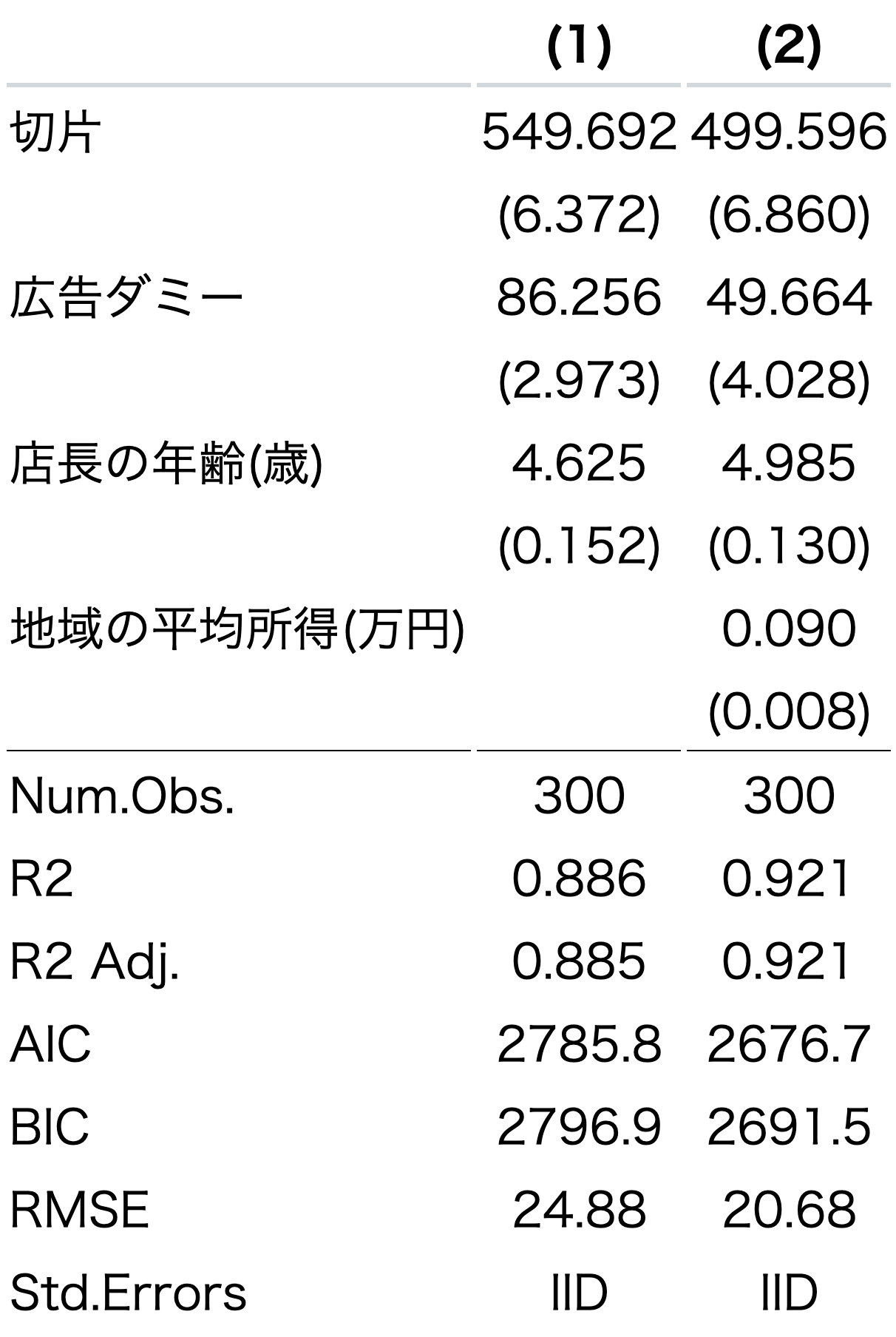
すると、対応する変数の名前が変換された表が表示される。
19.3.3 有意水準を示す星の表示
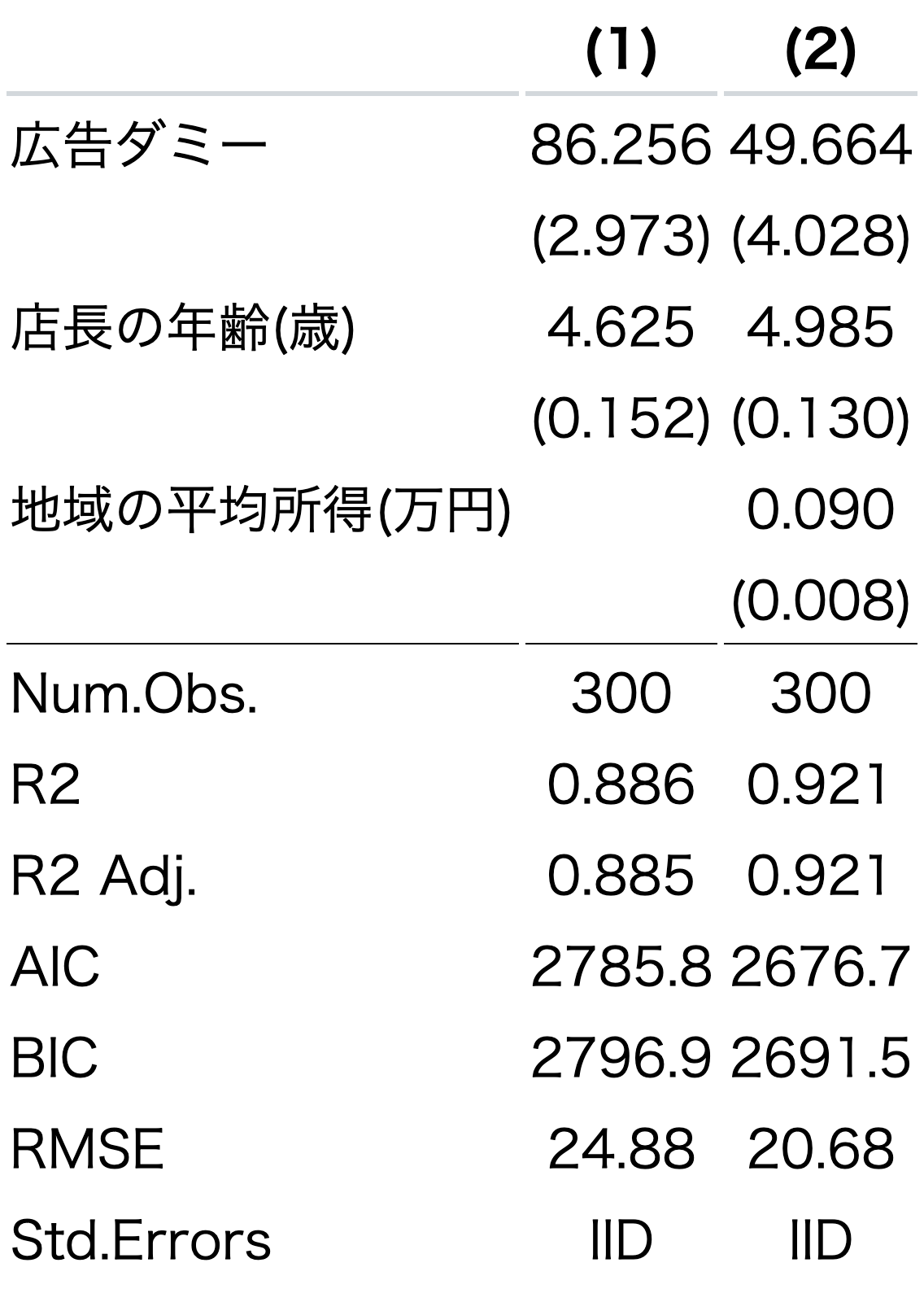
デフォルトでは、modelsummaryは有意水準を示す星(*)が非表示になっている。
表示させるためには、starsという引数にTRUEを指定する。
modelsummary(list(model1,model2),
coef_rename = varname_dict,
coef_omit = "Intercept",
stars = TRUE)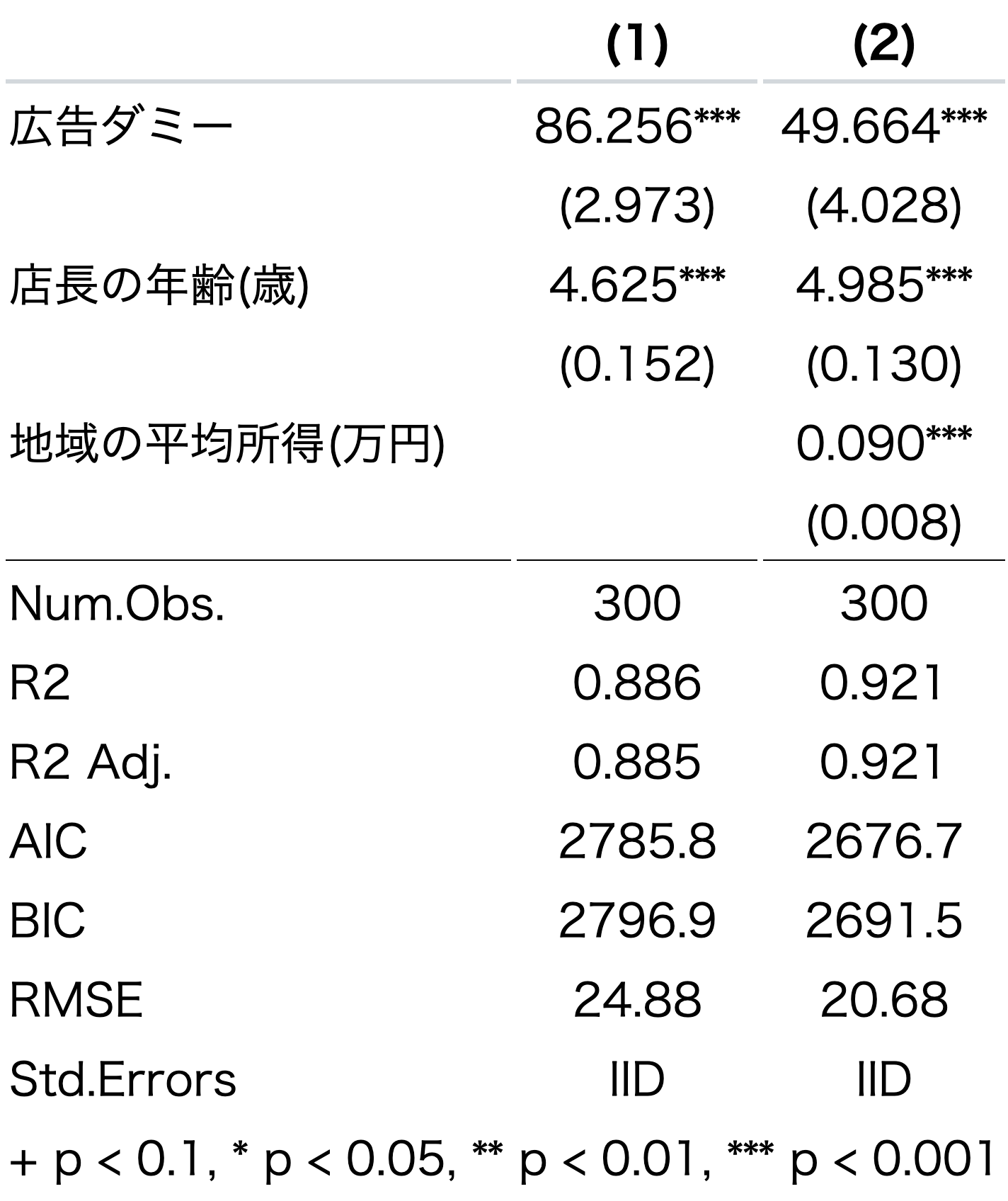 ここでは、有意水準が10%以下で
ここでは、有意水準が10%以下で+, 5%以下で*, 1%以下で**, 10%以下で***と表示される設定になっている。この基準も自動的に表の下部に表示される。
19.3.4 不必要な統計量の非表示
気づいている人もいるかもしれないが、表示された表の下部をみると、モデルの決定係数R2や調整済み決定係数R2 Adj.の他にもAICなどの統計量が表示されている。これは、もっと違う手法を使う場合は表示する必要だが、最小二乗法を使う基本的な回帰分析では表示する必要はない。
これをどうすれば非表示にできるかというと、gof_omitという引数で指定する。
modelsummary(list(model1,model2),
coef_rename = varname_dict,
coef_omit = "Intercept",
stars = TRUE,
gof_omit = "BIC|AIC|RMSE|Std.Errors")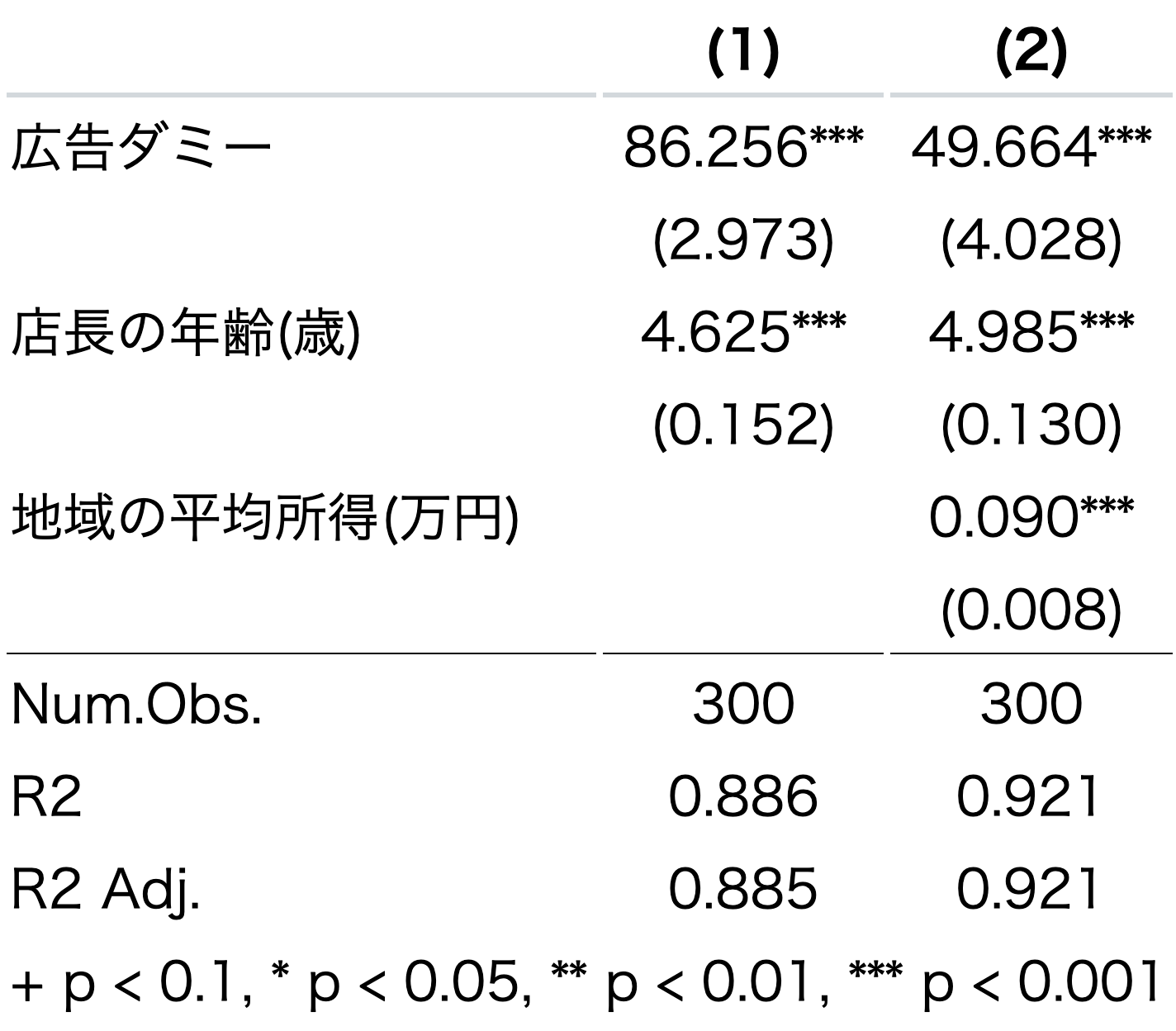
データの観察数、決定係数、調整済み決定係数以外の統計量が非表示になった。
19.3.5 モデルに名前をつける
各モデルの列は、入力された順番に(1),(2)という数字が自動でつくようになっているが、これに名前をつけることができる。
名前をつけるには、list()で入力するときに名前を指定する。
modelsummary(list("モデル1"=model1,"モデル2"=model2),
coef_rename = varname_dict,
coef_omit = "Intercept",
stars = TRUE,
gof_omit = "BIC|AIC|RMSE|Std.Errors")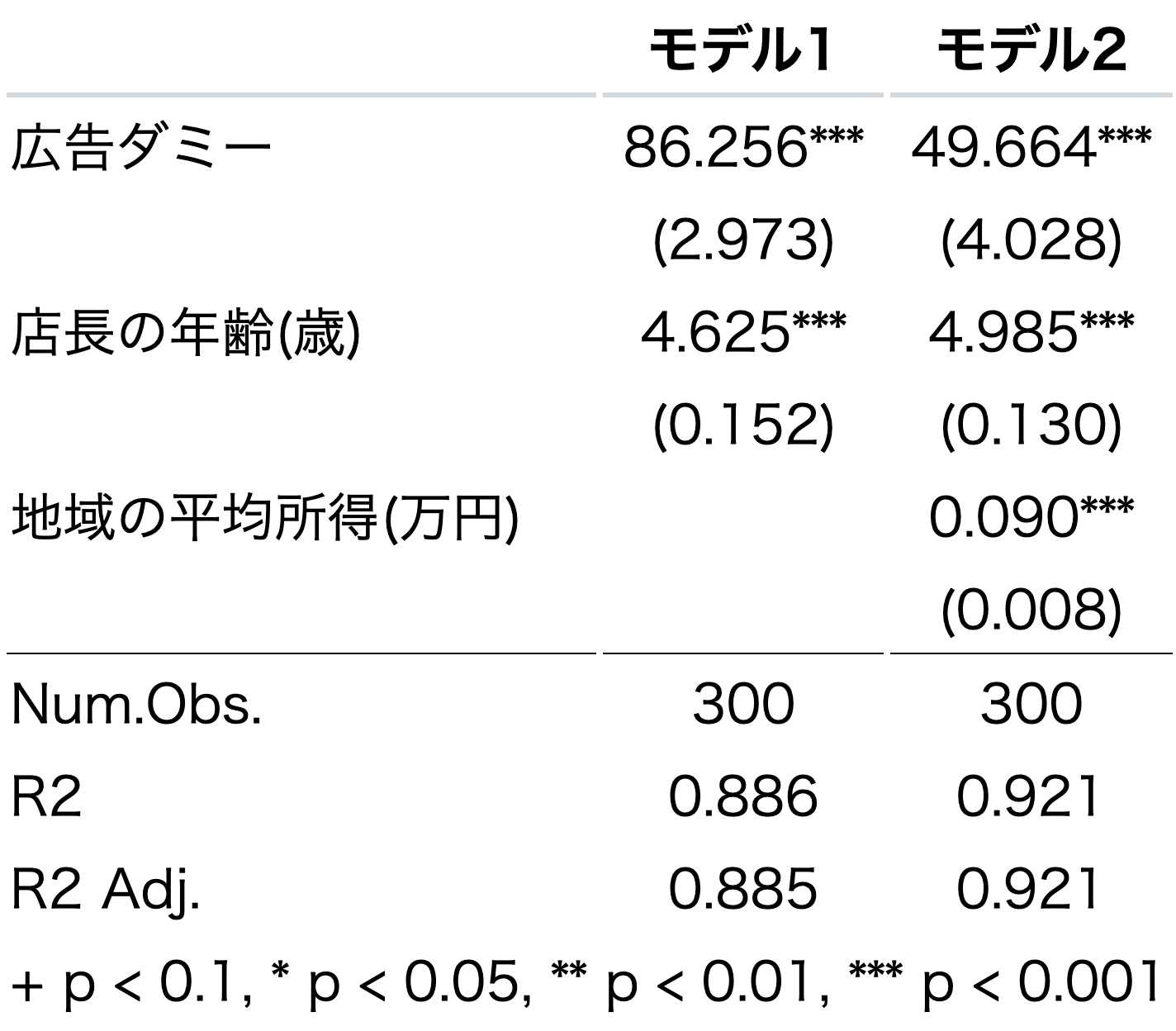
19.3.6 固定効果の表示
固定効果の場合は、固定効果自体をテーブルに表示することは数が多すぎて難しい。しかし、モデルに固定効果を含めているかどうかを表示することは重要だ。
modelsummary()では固定効果が含まれているかをX印で表示することを自動でやってくれる。
ここではパネルデータの章の例を使って、表の出力を見てみる。
単回帰モデルと固定効果モデルの両方を推定してオブジェクトにそれぞれ保存する。
reg1_panel <- feols(fatal_rate ~ beertax, data=data_f2)
reg1_panel_fe = feols(fatal_rate ~ beertax | state, data = data_f2)2つのモデルを並べた表を作成する。
ここでは単回帰モデル(reg1_panel)を「単回帰」, 固定効果モデル(reg1_panel)を「固定効果」と名前をつけている。
varname_dict2 = c(beertax="ビール税")
modelsummary(list("単回帰"=reg1_panel, "固定効果"=reg1_panel_fe),
coef_rename = varname_dict2,
coef_omit = "Intercept",
stars = TRUE,
gof_omit = "BIC|AIC|RMSE|Std.Errors"
)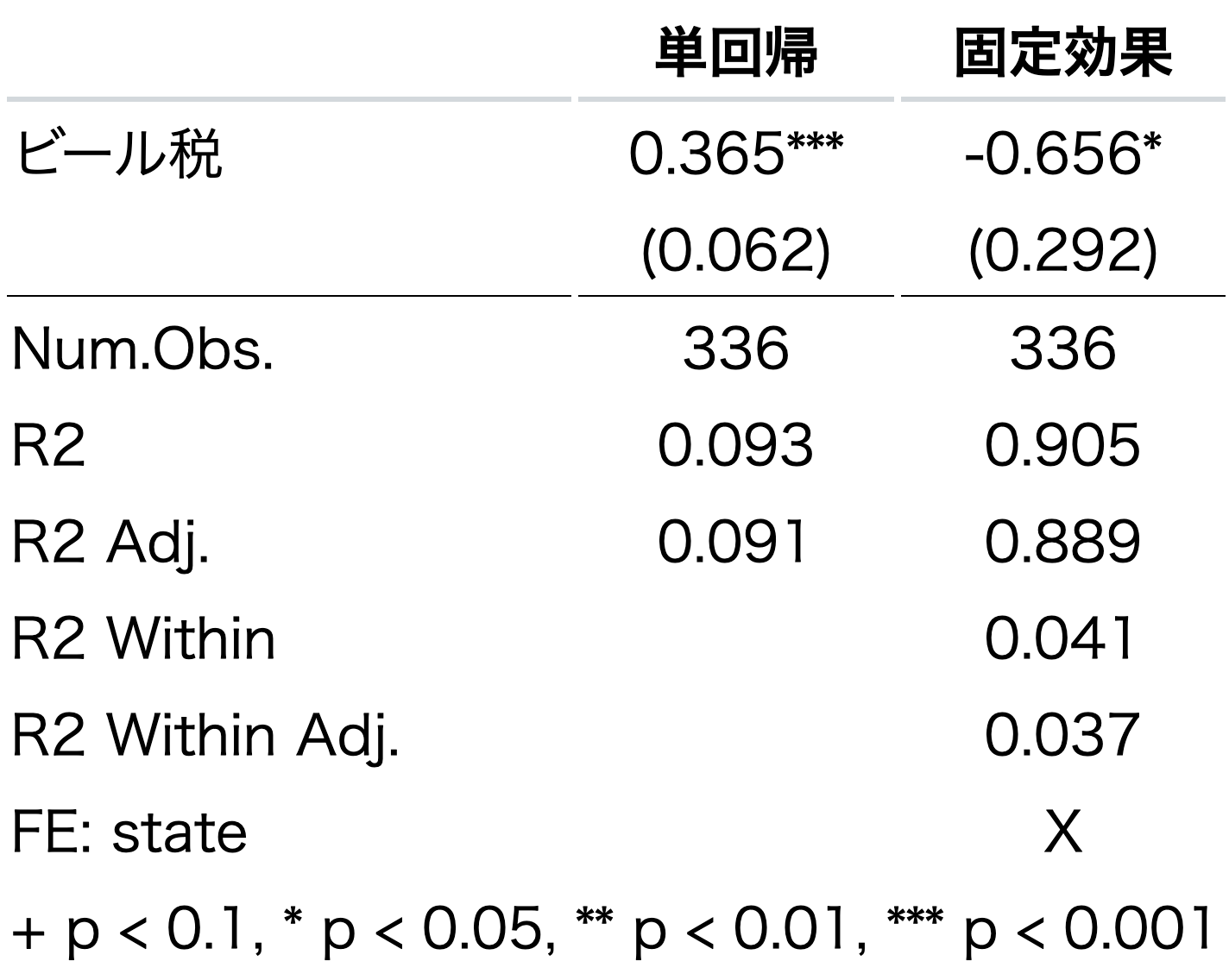
一番下にFE: stateという行が作成され、固定効果を含まないモデルは空欄、含むモデルにはX印がついている。
19.3.7 ファイルへの出力
modelsummaryではoutputという引数にファイル名を指定することで表をファイルに出力することができる。
ファイル形式は、.docx, .html, .tex, .md, .txt, .csv, .xlsx, .png, .jpgなどが対応している。
19.3.7.1 画像ファイルへの出力
output引数に画像ファイルの拡張子で終わるファイル名をつけると、画像ファイルが出力される。
modelsummary(list("モデル1"=model1,"モデル2"=model2),
coef_rename = varname_dict,
coef_omit = "Intercept",
stars = TRUE,
gof_omit = "BIC|AIC|RMSE|Std.Errors",
output="reg_output1.png")上のコードを実行してエラーが出なければ、作業ディレクトリの直下に”reg_output1.png”という画像ファイルが出力されているはずである。
19.3.7.2 ワードへの出力
Mircosoft Wordへの出力も画像と同様にoutput引数にファイル名を指定し、拡張子を”.docx”とすれば、出力することができる。
modelsummary(list("モデル1"=model1,"モデル2"=model2),
coef_rename = varname_dict,
coef_omit = "Intercept",
stars = TRUE,
gof_omit = "BIC|AIC|RMSE|Std.Errors",
output="reg_output1.docx")ここで注意点は、ワードファイルに日本語を含む表を出力するとうまくいかないという点である。 これは一般的には英語などはsingle-byte文字という半角アルファベットなどが使われるが、日本語はmulti-byte文字であり、開発者が日本語などを含むことを想定していないことから来ていると考えられる。
現状では日本語を使わないか、Wordファイルにした後に手作業で日本語に変換する、もしくは画像ファイルをWordに挿入するなどの対応になるだろう。
19.4 etable()による表作成
上述の通り、fixestのfeols()などで推定した結果のオブジェクトであれば、etable()を使って回帰分析表の形式で出力させることができる。
## model1 model2
## Dependent Var.: 支店の売上 支店の売上
##
## Constant 549.7*** (6.372) 499.6*** (6.860)
## 広告ダミー 86.26*** (2.973) 49.66*** (4.028)
## 店長の年齢(歳) 4.625*** (0.1515) 4.985*** (0.1299)
## 地域の平均所得(万円) 0.0899*** (0.0078)
## _______________ _________________ __________________
## S.E. type IID IID
## Observations 300 300
## R2 0.88607 0.92132
## Adj. R2 0.88530 0.92052
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1しかし、etable()の弱点として、Wordのファイルに出力しにくいという欠点がある。
19.4.1 変数名の設定
ここで、モデル推定に直接使用した説明変数の変数名は、読者にとってはわかりにくい。 もっとわかりやすい名前に変えて表に示すほうが親切である。
これは、setFixest_dict()という関数で設定することができる。
変数名と変換したい名前を=つなぎ、c()でまとめたものをsetFixest_dict()で囲ってやればよい。
これを設定したら、該当箇所が変換された表が出力される。
## model1 model2
## Dependent Var.: 支店の売上 支店の売上
##
## Constant 549.7*** (6.372) 499.6*** (6.860)
## 広告ダミー 86.26*** (2.973) 49.66*** (4.028)
## 店長の年齢(歳) 4.625*** (0.1515) 4.985*** (0.1299)
## 地域の平均所得(万円) 0.0899*** (0.0078)
## _______________ _________________ __________________
## S.E. type IID IID
## Observations 300 300
## R2 0.88607 0.92132
## Adj. R2 0.88530 0.92052
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 119.4.2 標準誤差の数値を係数の下に表示
se.below = TRUEを追加すると、標準誤差の数値を係数の下に表示する。
横幅をあまり取らないし、一般的にはこのような形で表示するのがスタンダードである。
## model1 model2
## Dependent Var.: 支店の売上 支店の売上
##
## Constant 549.7*** 499.6***
## (6.372) (6.860)
## 広告ダミー 86.26*** 49.66***
## (2.973) (4.028)
## 店長の年齢(歳) 4.625*** 4.985***
## (0.1515) (0.1299)
## 地域の平均所得(万円) 0.0899***
## (0.0078)
## _______________ __________ ___________
## S.E. type IID IID
## Observations 300 300
## R2 0.88607 0.92132
## Adj. R2 0.88530 0.92052
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1